
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- MySQL
- JSON
- API
- Linux
- DATABASE
- GIT
- github
- commands
- .gitignore
- SCV
- noob
- ansible
- Django
- Anime
- Filecoin
- crawler
- cached
- Classes
- Jupyter Notebook
- Methods
- directories
- basics
- workbench
- strings
- forks
- pandas
- Blockchain
- python
- MyAnimeList
- project
- Today
- Total
제니 블로그
MyAnimeList Web Crawler 본문
02/14/2023
For the future, we plan on scrapping reviews from anime to further the sentimental analysis.
As an example, we got the reviews for the anime Fullmetal Alchemist, and created a web crawler.
IDE: Jupyter Notebook (Python)
import requests
from bs4 import BeautifulSoup
base_url = "https://myanimelist.net/anime/5114/Fullmetal_Alchemist__Brotherhood/reviews"
review_texts = []
# from pages 1 ~ 11
for i in range(1, 11):
url = f"{base_url}?p={i}"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
reviews = soup.find_all("div", {"class": "text"})
review_texts += [review.text.strip() for review in reviews]
for review_text in review_texts:
print(review_text)
For this code block, we imported the necessary libraries for web crawler, requests and BeautifulSoup. This resulted in printing out all the reviews on page 1-10 of the reviews section.

Now to save this data to a csv (comma separted values) file :
import csv
with open("reviews.csv", "w", newline="", encoding="utf-8") as csvfile:
writer = csv.writer(csvfile)
for review_text in review_texts:
writer.writerow([review_text])There's another way of writing this, using the pandas library, which provides the same result.
import pandas as pd
df = pd.DataFrame(review_texts, columns=["review_text"])
df.to_csv("reviews.csv", index=False, encoding="utf-8")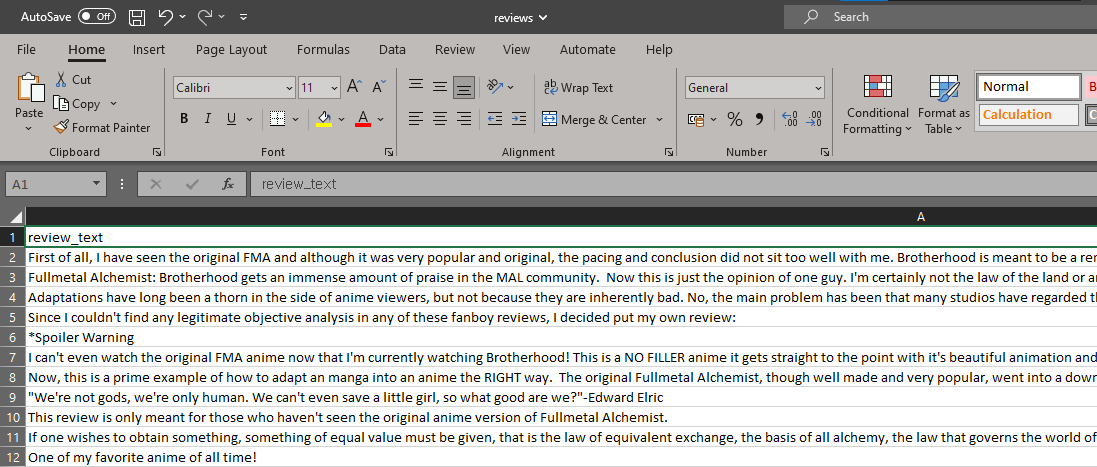
This has to add some of other features, like what anime that the user would like to know about. Still in progress! TBD!!!
We plan to later save this to a database of some sort, and have the data saved there for easier usage.
There's a long way to go, but this is still progress :)

'Project' 카테고리의 다른 글
| Making a Database Schema (0) | 2023.03.01 |
|---|---|
| Text Preprocessing (0) | 2023.02.25 |
| Getting the Data from API (0) | 2023.02.21 |
| Getting the Forum ID for episode discussions (0) | 2023.02.19 |
| Using API from MyAnimeList and making a Database (0) | 2023.02.15 |



