
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- directories
- crawler
- basics
- Classes
- Blockchain
- MyAnimeList
- pandas
- project
- .gitignore
- DATABASE
- python
- workbench
- GIT
- Anime
- Jupyter Notebook
- Django
- strings
- commands
- ansible
- Methods
- API
- forks
- Filecoin
- cached
- MySQL
- noob
- JSON
- SCV
- github
- Linux
- Today
- Total
제니 블로그
Getting the Forum ID for episode discussions 본문
When an episode airs, MAL posts discussions for every episode. For example, the anime Bleach has 366 episode discussion posts. Each of them has an unique forum ID, which we can get from web crawling.
We plan on getting the ID of each forum post, and then apply the API to get all the comments from the users that shows their opinions and feelings about that certain episode.
This is an experiement of this project, and I think it is on a positive direction ATM.

Making a web crawler is basic. Jupyter Notebook has a very clean UI that is easily readable and allows users to interactrively develop and test the code. In the field of data science, it provides many data analysis and visualization tools by organizing code into cells that are ran independently.
import requests # send HTTP requests (GET/POST) to web servers
from bs4 import BeautifulSoup # sets up HTML/XML parserThese are the libraries that we will be using throughout the project.
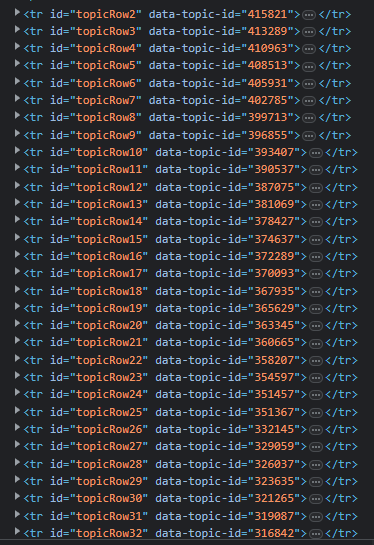
We want those ID numbers so we will be using those elements for the parser.
url = f"https://myanimelist.net/forum/?animeid={anime_id}&topic=episode&show={shows}"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
rows = soup.find_all('tr', {'id': lambda x: x and x.startswith('topicRow')})This snippet will make a get request to the URL and select all HTML `tr` tags that have an `id` attribute starting with the string "topicRow".
The lambda function will check if the value of the id attribute starts with "topicRow", x representing the value of the id attribute for each tr tag that is being searched.
The full code ends up being :
def get_forum_ids(anime_id):
shows = 0
page_num = 1
while True:
# construct the URL for the current page number
url = f"https://myanimelist.net/forum/?animeid={anime_id}&topic=episode&show={shows}"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
rows = soup.find_all('tr', {'id': lambda x: x and x.startswith('topicRow')})
if not rows:
break
t_id = []
for row in rows:
t_id.append(row['data-topic-id'])
print(f"Forum IDs for page {page_num}: {t_id}")
shows += 50 # 50 forum posts for each page
page_num += 1
get_forum_ids(269)The forum board of episodes start with &show=0, showing the latest episode discussions. It will start from page 1 of the board to until when show= the first episode.
This will create a list for the IDs in each forum post.

The values from the list will be used for the information we need for the analylsis later on!
'Project' 카테고리의 다른 글
| Making a Database Schema (0) | 2023.03.01 |
|---|---|
| Text Preprocessing (0) | 2023.02.25 |
| Getting the Data from API (0) | 2023.02.21 |
| MyAnimeList Web Crawler (0) | 2023.02.16 |
| Using API from MyAnimeList and making a Database (0) | 2023.02.15 |



